机器学习——博客推荐系统
前言
在当今的信息时代,技术博客已成为知识、见解和娱乐的重要来源。随着博客内容的日益丰富,找到最相关和最引人入胜的文章对用户来说可能是一项艰巨的任务。为了应对这一挑战,我们需要一个全面的博客推荐系统,利用尖端技术和机器学习算法来增强博客平台上的用户体验。
数据集下载:机器学习之博客推荐系统数据集
我们将基于发布的博客推荐数据构建博客推荐系统。其中包括从 Medium 收集的博客数据以及通过跟踪他们的活动从 5000 多名用户收集的评级。
这里有两种类型的推荐系统,分别是:
一、协同过滤
协同过滤是一种流行的推荐技术,它利用用户的集体智慧来提出建议。它分析用户行为和项目相似性,以识别模式并生成个性化建议。协同过滤中有两种主要方法:
1、基于用户的协同筛选:
此方法根据类似用户的首选项向用户推荐项目。它识别具有相似品味的用户,并推荐这些相似用户喜欢的项目。例如,如果用户 A 和用户 B 具有相似的首选项,并且用户 A 喜欢特定的博客文章,则系统会向用户 B 推荐该文章。
2、基于项目的协同筛选:
基于项目的协同筛选不是关注相似的用户,而是推荐与用户以前享受的项目相似的项目。它分析项目之间的关系,并根据它们的相似性建议新项目。例如,如果用户 A 喜欢博客文章 X,并且博客文章 Y 类似于博客文章 X,则系统会向用户 A 推荐博客文章 Y。
二、基于内容的过滤
基于内容的筛选根据项目的属性或特征推荐项目。它使用用户首选项和项目功能来提出建议。此方法根据用户的历史首选项和项目属性构建用户配置文件。然后,它会推荐符合用户偏好并具有类似功能的项目。例如,如果用户对与技术相关的博客文章表现出兴趣,系统将推荐更多具有类似技术主题的文章。
混合推荐系统:混合推荐系统结合了多种推荐方法,以提供更准确和多样化的建议。他们利用不同技术的优势来克服限制并提供增强的建议。例如,混合系统可能会将协作过滤和基于内容的过滤结合起来,以平衡用户首选项和项目属性。通过使用协同过滤来捕获用户行为,并使用基于内容的筛选来捕获项目特征,混合系统可以提供更准确和个性化的建议。
这里将使用基于内容的过滤方法来构建博客推荐系统。
# import required packages
import pandas as pd
import numpy as np
import nltk
import re
from nltk import corpus
from nltk.stem import WordNetLemmatizer
from nltk.stem import PorterStemmer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from nltk import wsd
from nltk.corpus import wordnet as wn
nltk.download('omw-1.4')
nltk.download('wordnet')
nltk.download('wordnet2022')
! cp -rf /usr/share/nltk_data/corpora/wordnet2022 /usr/share/nltk_data/corpora/wordnet # temp fix for lookup error.加载数据
blog_df = pd.read_csv('../data/blog_data/Medium_Blog_Data.csv')
author_df = pd.read_csv('../data/blog_data/Author_Data.csv')
ratings_df = pd.read_csv('../data/blog_data/Blog_Ratings.csv')数据集字段说明
第一个数据集具有以下字段:
blog_id:赋予博客的唯一ID
author_id:给予博客作者的唯一ID
blog_title : 博客标题
blog _ conten:博客内容的简要摘要
blog_link : 链接到特定博客
blog_img:与该博客相关的图像
blog_topic :它所属的域,例如。人工智能、数据科学等
第二个数据集具有以下字段:
author_id:赋予作者的唯一ID
author_name : 作者姓名
第三个数据集具有以下字段:
blog_id : 博客的ID
user_id : 用户的 ID
ratings:用户给出的评分
内容筛选与数据处理
首先,让我们看看这个Medium_Blog_Data数据集中的topic栏每个分类里有多少篇博文
blog_df['topic'].value_counts()ai 736
blockchain 644
cybersecurity 642
web-development 635
data-analysis 594
cloud-computing 589
security 527
web3 471
machine-learning 467
nlp 453
data-science 444
deep-learning 430
android 426
dev-ops 384
information-security 374
image-processing 354
flutter 343
backend 341
cloud-services 339
Cryptocurrency 331
app-development 322
backend-development 312
Software-Development 309
Name: topic, dtype: int64从博客数据中删除不需要的列,经过分析,其中的author_id、blog_link、blog_img和scrape_time是我们不需要的列,需要删除它们。
blog_df.drop(['author_id','blog_link','blog_img','scrape_time'],axis='columns',inplace=True)接着,需要删除博客数据中重复出现的内容
blog_df.drop_duplicates(['blog_title','blog_content'],inplace=True)预处理文本数据
必须要从博客内容中删除停用词,并使用词序列化将所有单词放到根词表中,这是为了后面的操作需要执行的基本步骤
lst_stopwords=corpus.stopwords.words('english')
def pre_process_text(text, flg_stemm=False, flg_lemm=True, lst_stopwords=None):
text=str(text).lower()
text=text.strip()
text = re.sub(r'[^\w\s]', '', text)
lst_text = text.split()
if lst_stopwords is not None:
lst_text=[word for word in lst_text if word not in lst_stopwords]
if flg_lemm:
lemmatizer = WordNetLemmatizer()
lst_text = [lemmatizer.lemmatize(word) for word in lst_text]
if flg_stemm:
stemmer = PorterStemmer()
lst_text = [stemmer.stem(word) for word in lst_text]
text=" ".join(lst_text)
return textblog_df['clean_blog_content'] = blog_df['blog_content'].apply(lambda x: pre_process_text(x,flg_stemm=False,flg_lemm=True,lst_stopwords=lst_stopwords))使用TFIDF矢量器对博客内容进行矢量化
TF-IDF是术语频率逆文档频率的缩写,是自然语言处理和信息检索中广泛使用的一种技术,用于量化文档集合中某个术语在文档中的重要性。TF-IDF结合了两个因素:术语频率(TF)和逆文档频率(IDF)。
术语频率 (TF):TF 测量文档中术语的频率。它计算术语在文档中出现的次数,并将其表示为原始计数或规范化值。TF 背后的基本原理是,在文档中出现频率更高的术语可能与该文档更重要或更相关。
反向文档频率 (IDF):IDF 衡量术语在整个文档集合中的重要性。它计算包含该术语的文档数的倒数的对数。IDF 背后的想法是,出现在少量文档中的术语比出现在大量文档中的术语更具信息性和价值。
TF-IDF 计算是通过将 TF 和 IDF 值相乘来执行的。生成的分数表示文档中的术语在整个文档集合上下文中的重要性。分数越高,表示术语与特定文档更相关或更独特。
计算文档集合中文档 (d) 中术语 (t) 的 TF-IDF 的公式如下:

tfidf_vecotorizer = TfidfVectorizer()
tfidf_matrix = tfidf_vecotorizer.fit_transform(blog_df['clean_blog_content'])
print(tfidf_matrix.shape)(10466, 25157)因此,这里有25157 个唯一的单词或向量,用于描述我们数据集中的数量,总共 10467 个博文。
使用余弦相似性进行基于内容的过滤
余弦相似性是用于确定多维空间中两个向量之间的相似性的度量。它计算矢量之间角度的余弦,这表明矢量在方向和方向方面的相关性。
这是计算余弦相似性的公式,
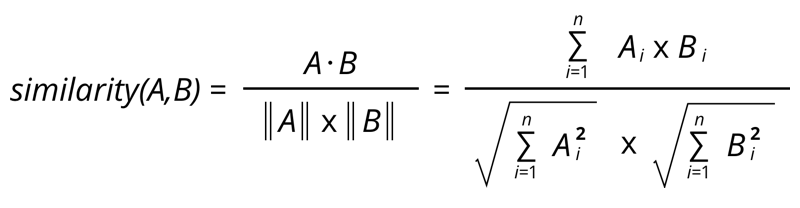
它将根据两个向量之间的距离返回它们的相似程度。此值的范围为 0 到 1 。其中 0 表示最不相似的内容,1 表示最相似的内容。它是构建基于内容的推荐系统的非常广泛使用和有效的方法。这也是我们使用它来构建博客推荐系统的唯一原因。
cosine_sim = cosine_similarity(tfidf_matrix)
print(cosine_sim)[[1. 0. 0. ... 0.02173711 0. 0. ]
[0. 1. 0. ... 0.00452585 0.00905365 0.00985712]
[0. 0. 1. ... 0. 0. 0. ]
...
[0.02173711 0.00452585 0. ... 1. 0. 0. ]
[0. 0.00905365 0. ... 0. 1. 0.03097127]
[0. 0.00985712 0. ... 0. 0.03097127 1. ]]# Let us have the blogs rated by user with user id 12
user_rating = ratings_df[ratings_df['userId']==12]
# consider blogs with ratings greater than or equal to 3.5 just for simplification
blogs_to_consider = user_rating[user_rating['ratings']>=3.5]['blog_id']
# Now we need Id's of this blogs in form of a list
high_rated_blogs = blogs_to_consider.valuesrated_blogs = blog_df[blog_df['blog_id'].isin(high_rated_blogs)]
rated_blogs推荐函数实现
根据博客的相似程度创建一个推荐博客的函数。
def get_similar_blog(high_rated_blogs):
"""
Args:
high_rated_blogs : list of blog id's of the blogs rated by the user
Returns:
recommended_blogs : list of blog id's of the blogs that are to be recommended
"""
recommended_blogs = []
for blog_id in high_rated_blogs:
# Find out the index value of particular blog
temp_id = blog_df[blog_df['blog_id'] == blog_id].index.values[0]
# Find out the index value of all the blogs which have similarity greater than 0.95
temp_blog_id = blog_df[cosine_sim[temp_id] > 0.95]['blog_id'].index.values
# Check whether the blog is already recommended or not and also verify that it is not seen by user previously
for b_id in temp_blog_id:
if b_id not in recommended_blogs and b_id not in high_rated_blogs:
recommended_blogs.append(b_id)
return recommended_blogsrecommended_blogs=get_similar_blog(high_rated_blogs)blog_df.iloc[recommended_blogs]到此,博客推荐的方法已经实现完成。感谢您的阅读,如果对你有所帮助,麻烦帮忙点个赞,收藏转发一下,谢谢!





