Tensorflow卷积神经网络
前言
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络, 在计算机视觉等领域被广泛应用. 本文将简单介绍其原理并分析Tensorflow官方提供的示例.
了解卷积神经网络
什么是卷积
卷积是图像处理中一种基本方法. 卷积核是一个f*f的矩阵. 通常n取奇数,使得卷积核有中心点.
对图像中每个点取以其为中心的f阶方阵, 将该方阵中各值与卷积核中对应位置的值相乘, 并用它们的和作为结果矩阵中对应点的值.
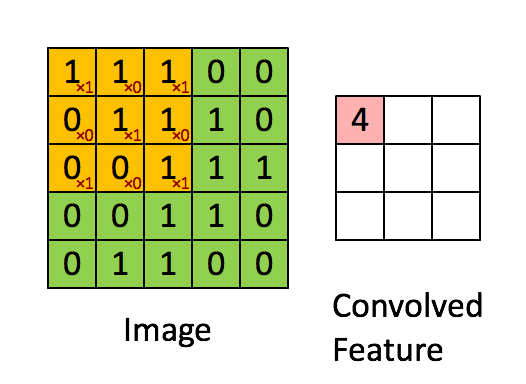
1*1 + 1*0 + 1*1 + 0*0 + 1*1 + 1*0 + 0*1 + 0*0 + 1*1 = 4
卷积核每次向右移动1列, 遇行末向下移动1列直到完成所有计算. 我们把每次移动的距离称为步幅s.
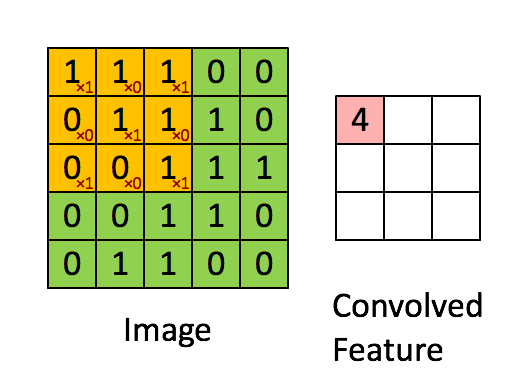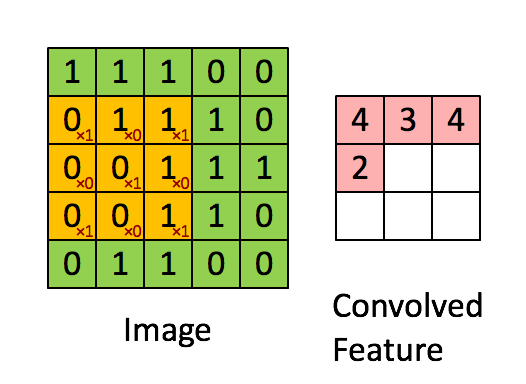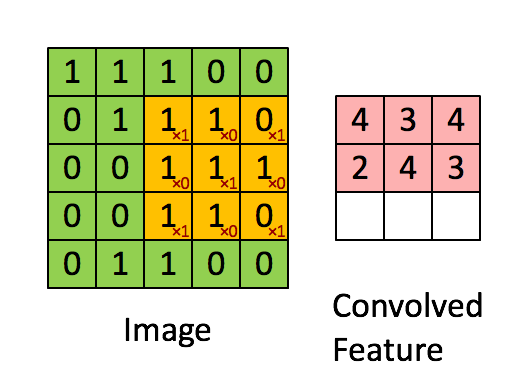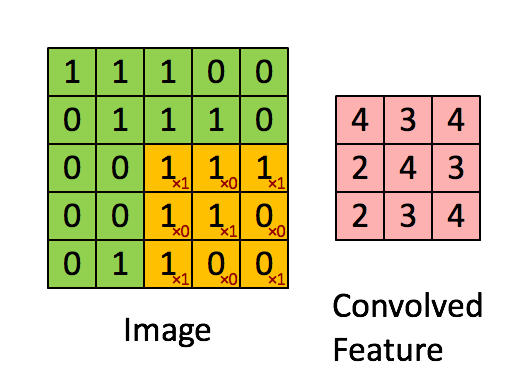
上述操作处理图像得到新图像的操作称为卷积, 在图像处理中卷积核也被称为过滤器(filter).
卷积得到的结果矩阵通常用于表示原图的某种特征(如边缘), 因此卷积结果被称为特征图(Feature Map).
每个卷积核可以包含一个偏置参数b, 即对卷积结果的每一个元素都加b作为输出的特征图.
边缘检测是卷积的一种典型应用, 人眼所见的边缘是图像中不同区域的分界线. 分界线两侧的色彩或灰度通常有着较大的不同.

下面我们使用一个非常简单的示例来展示边缘检测过程. 第一个6*6的矩阵是灰度图, 显然图像左侧较亮右侧较暗, 中间形成了一条明显的垂直边缘.
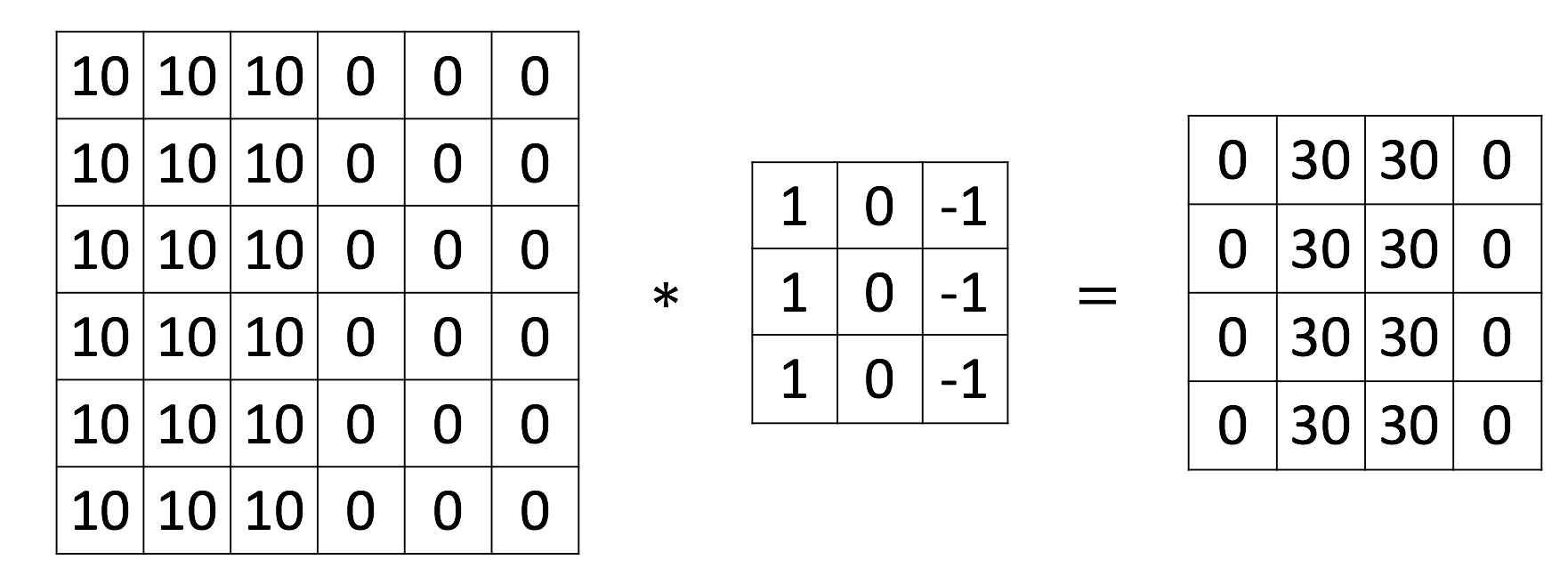
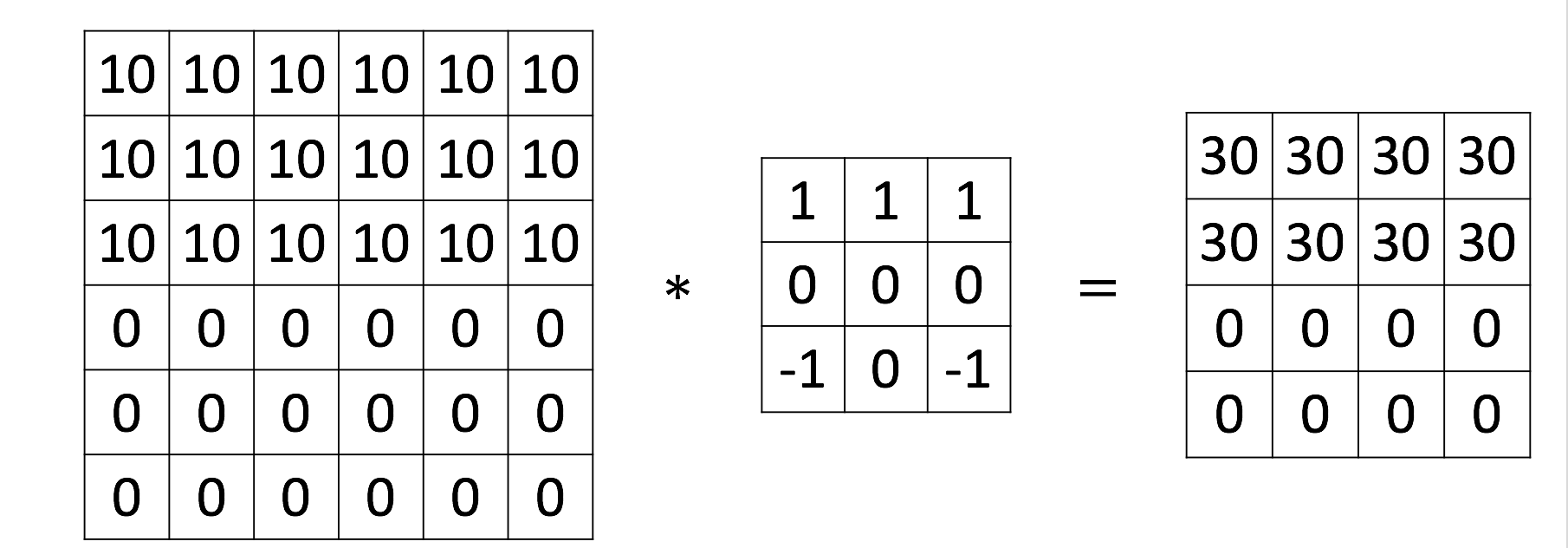
在特征图中央有一条垂直亮线(第2,3列), 即原图的垂直边缘. 类似的可以检测纵向边缘:
卷积核的中心无法对准原图像中边缘的像素点(与边缘距离小于卷积核半径), 若要对边缘的点进行计算必须填充(padding)外部缺少的点使卷积核的中心可以对准它们. 常用的填充策略有:
- SAME: 使用附近点的值代替缺失的点, 可以保证特征图不会变小
- VALID: 只对可用的位置进行卷积(不进行填充), 但特征图会变小
此外还有0值填充, 均值填充等方法. 通常用p来描述填充的宽度.
SAME填充效果, 4*4矩阵被填充为6*6矩阵, 填充宽度p=1:
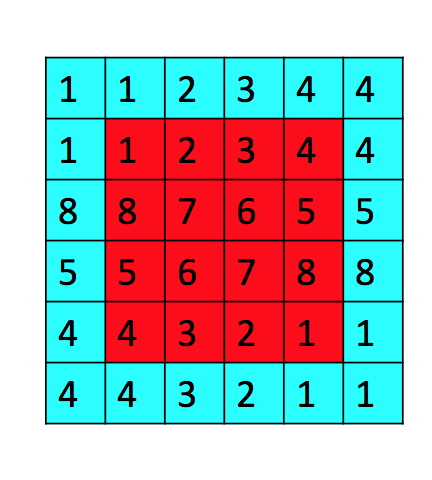
对于n*n的矩阵, 使用f*f的核进行卷积, 填充宽度为p, 若纵向步幅为s1, 横向步幅为s2则特征图的行列数为:
三维卷积
灰度图所能描述的信息的极为有限, 我们更多地处理RGB图像. RGB图像需要3个矩阵才能描述图片, 我们称为3个通道(channel).
以下图6*6的RGB图为例, 3个矩阵分别与黄色卷积核进行卷积得到3个4*4特征图, 将3个特征图同位置的值叠加得到最终的卷积结果.

在边缘检测中我们注意到, 一个卷积核通常只能提取图像一种特征如水平边缘或垂直边缘. 为了提取图像的多个特征, 我们通常使用多个卷积核.
我们使用高维矩阵来描述这一过程, RGB图像为6*6*3矩阵, 两个卷积核叠加为3*3*2矩阵, 两个特征图叠加为4*4*2矩阵. 输入, 输出和卷积核均使用三维矩阵来表示, 这样我们可以方便的级联多个卷积层.
为什么使用卷积
在上一节中我们已经介绍了一个卷积层如何工作的, 现在我们来探讨为什么使用卷积提取图像特征.
首先分析卷积层的输入输出, 每个卷积层输入了一个w1 * h1 * c1 的三维矩阵, 输出w2 * h2 *c2的三维矩阵.
若使用全连接层需要(w1 * h1 * c1) * (w2 * h2 *c2)个参数, 卷积层只需要训练c2个二维卷积核中的f1 * f1 * c2个参数和c2个偏置值, 可见卷积层极大地减少了参数的数量.
更少的参数对于训练数据和计算资源都有限的任务而言, 通常意味着更高的精度和更好的训练效率.
更重要的是, 卷积针对小块区域而不是单个像素进行处理, 更好地从空间分布中提取特征, 这与人类视觉是类似的. 而全连接层严重忽略了空间分布所包含的信息.
特征图中一个像素只与输入矩阵中f * f个像素有关, 这种性质被称为局部感知. 一个卷积核用于生成特征图中所有像素, 该特性被称为权值共享.
池化
通过卷积学习到的图像特征仍然数量巨大, 不便直接进行分类. 池化层便用于减少特征数量.
池化操作非常简单, 比如我们使用一个卷积核对一张图片进行过滤得到一个8x8的方阵, 我们可以将方阵划分为16个2x2方阵, 每个小方阵称为邻域.
用16个小方阵的均值组成一个4x4方阵便是均值池化, 类似地还有最大值池化等操作. 均值池化对保留背景等特征较好, 最大值池化对纹理提取更好.
随机池化则是根据像素点数值大小赋予概率(权值), 然后按其加权求和.
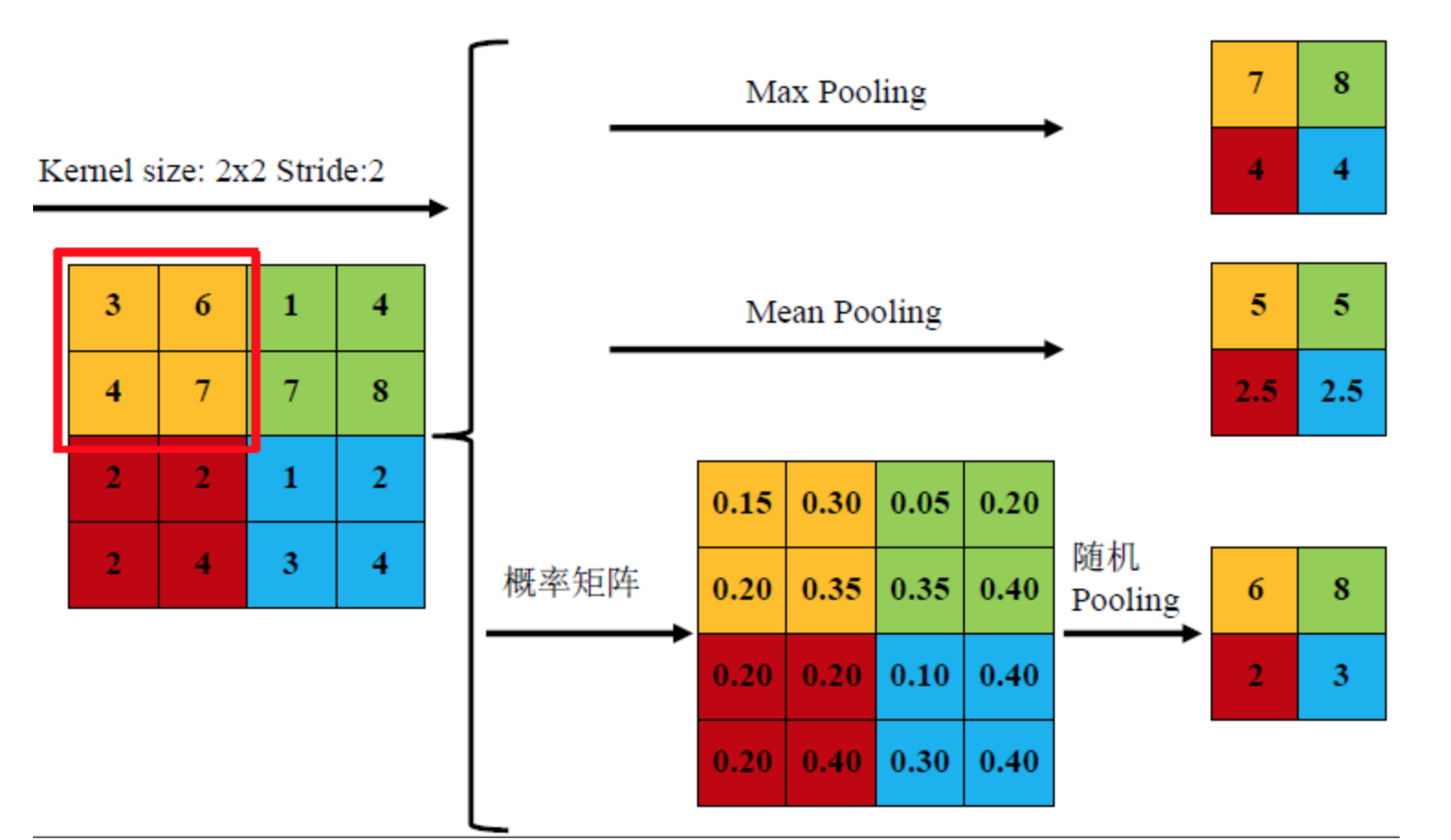
池化操作用于减少图的宽度和高度, 但不能减少通道数.
用1*1*c2的核进行卷积可以使w1 * h1 * c1的输入矩阵映射到w1 * h1 * c2的输出矩阵. 即对各通道输出加权求和实现减少通道数的效果.
TensorFlow实现
TensorFlow的文档Deep MNIST for Experts介绍了使用CNN在MNIST数据集上识别手写数字的方法., 该示例采用了LeNet5模型.
完整代码可以在GitHub上找到, 本文将对其进行简单分析. 源码来自tensorflow-1.3.0版本示例.
主要有3条引入:
import tempfile
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
main(_)函数负责网络的构建:
def main(_):
# 导入MNIST数据集
# FLAGS.data_dir是本地数据的路径, 可以用空字符串代替以自动下载数据集
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)
# x是输入层, 每个28x28的图像被展开为784阶向量
x = tf.placeholder(tf.float32, [None, 784])
# y_是训练集预标注好的结果, 采用one-hot的方法表示10种分类
y_ = tf.placeholder(tf.float32, [None, 10])
# deepnn方法构建了一个cnn, y_conv是cnn的预测输出
# keep_prob是dropout层的参数, 下文再讲
y_conv, keep_prob = deepnn(x)
# 计算预测y_conv和标签y_的交叉熵作为损失函数
with tf.name_scope('loss'):
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=y_,
logits=y_conv)
cross_entropy = tf.reduce_mean(cross_entropy)
# 使用Adam优化算法, 以最小化损失函数为目标
with tf.name_scope('adam_optimizer'):
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# 计算精确度(正确分类的样本数占测试样本数的比例), 用于评估模型效果
with tf.name_scope('accuracy'):
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
correct_prediction = tf.cast(correct_prediction, tf.float32)
accuracy = tf.reduce_mean(correct_prediction)
main函数与其它tensorflow神经网络并无二致, 关键分析deepnn方法如何构建cnn:
def deepnn(x):
# x的结构为[n, 784], 将其展开为[n, 28, 28]
# 灰度图只有一个通道, x_image第四维为1
# x_image的四维分别是[n_sample, width, height, channel]
with tf.name_scope('reshape'):
x_image = tf.reshape(x, [-1, 28, 28, 1])
# 第一个卷积层, 将28x28*1灰度图使用5*5*32核进行卷积
with tf.name_scope('conv1'):
# 初始化连接权值, 为了避免梯度消失权值使用正则分布进行初始化
W_conv1 = weight_variable([5, 5, 1, 32])
# 初始化偏置值, 这里使用的是0.1
b_conv1 = bias_variable([32])
# strides是卷积核移动的步幅. 采用SAME策略填充, 即使用相同值填充
# def conv2d(x, W):
# tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
# h_conv1的结构为[n, 28, 28, 32]
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
# 第一个池化层, 2*2最大值池化, 得到14*14矩阵
with tf.name_scope('pool1'):
h_pool1 = max_pool_2x2(h_conv1)
# 第二个卷积层, 将28*28*32特征图使用5*5*64核进行卷积
with tf.name_scope('conv2'):
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
# h_conv2的结构为[n, 14, 14, 64]
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
# 第二个池化层, 2*2最大值池化, 得到7*7矩阵
with tf.name_scope('pool2'):
# h_pool2的结构为[n, 7, 7, 64]
h_pool2 = max_pool_2x2(h_conv2)
# 第一个全连接层, 将7*7*64特征矩阵用全连接层映射到1024个特征
with tf.name_scope('fc1'):
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# 使用dropout层避免过拟合
# 即在训练过程中的一次迭代中, 随机选择一定比例的神经元不参与此次迭代
# 参与迭代的概率值由keep_prob指定, keep_prob=1.0为使用整个网络
with tf.name_scope('dropout'):
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 第二个全连接层, 将1024个特征映射到10个特征, 即10个分类的one-hot编码
# one-hot编码是指用 `100`代替1, `010`代替2, `001`代替3... 的编码方式
with tf.name_scope('fc2'):
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
return y_conv, keep_prob
整个网络暴露的接口有3个:
- 输入层
x[n, 784] - 输出层
y_conv[n, 10] - dropout保留比例
keep_prob[1]
现在可以继续关注main方法了, 完成网络构建之后main先将网络结构缓存到硬盘:
graph_location = tempfile.mkdtemp()
print('Saving graph to: %s' % graph_location)
train_writer = tf.summary.FileWriter(graph_location)
train_writer.add_graph(tf.get_default_graph())
接下来初始化tf.Session()进行训练:
with tf.Session() as sess:
# 初始化全局变量
sess.run(tf.global_variables_initializer())
for i in range(10000):
# 每次取训练数据集中50个样本, 分10000次取出
# batch[0]为特征集, 结构为[50, 784]即50组784阶向量
# batch[1]为标签集, 结构为[50, 10]即50个采用one-hot编码的标签
batch = mnist.train.next_batch(50)
# 每进行100次迭代评估一次精度
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x: batch[0], y_: batch[1], keep_prob: 1.0})
print('step %d, training accuracy %g' % (i, train_accuracy))
# 进行训练, dropout keep prob设为0.5
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
# 评估最终精度, dropout keep prob设为1.0即使用全部网络
print('test accuracy %g' % accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
启动代码会处理命令行参数和选项:
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--data_dir', type=str,
default='/tmp/tensorflow/mnist/input_data',
help='Directory for storing input data')
FLAGS, unparsed = parser.parse_known_args()
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)




